

苹果在自家机器学习日报(machinelearning.apple.com)自爆功法,发布论文《基于深度神经网络的设备端人脸辨识》(An On-device Deep Neural Network for Face Detection),披露脸部辨识技术演变。
2017 年 9 月 13 日(美国时间 12 日),苹果在乔布斯剧院发布智能手机 iPhone X。这款搭载 64 位架构 A11 神经处理引擎、采用脸部辨识解锁方式(Face ID)的全屏幕手机,号称 iPhone 10 周年纪念之作,售价8388元起。
事实上,苹果 iOS 10 就开始使用深度学习技术用于脸部辨识,目前已向开发者开放视觉框架,支持相关应用程序开发。下文将着重讨论电脑视觉技术在隐私保护遇到的挑战,及基于深度学习的终端机人脸辨识技术实现方案。
一、终端机深度学习模型的挑战
苹果最早发布的脸部辨识 API 是透过 CIDetector 达成,一种针对静态影响的特征资讯(包括人脸、几何图形、条码等)辨识的影像处理单元。最早版本的 CIDetector 基于维奥拉─琼斯目标侦测框架(Viola-Jones),苹果将其以传统方式最佳化。
后来,随着深度学习出现、电脑视觉领域的应用,人脸辨识的准确性得到大飞跃,启发了苹果。相比传统的电脑视觉方案,深度学习演算法能有更好的模型,也要求更多记忆、储存/磁盘和可计算资源(Computatioal resource)。
矛盾点来了:以目前终端机(智能手机)的硬件条件来看,基于深度学习的视觉模型似乎并不是可行方案,而大多数企业的解决方案是提供云界面(Cloud-Based API),先将图片传给能执行大型深度学习框架的服务器,然后用深度学习侦测脸部。而云服务往往需要强大的桌机系统级 GPU,需要大量存储器。
界面方案虽然可行,但违背了苹果的隐私保护理念,因此,苹果只提供照片和影片云服务,所有照片、影片上传之前需得到帐户许可;针对电脑视觉指令,上传云端被认为是不太合适的方法。
最终,苹果还是找到了在终端机,也就是 iPhone 上的深度学习方案,并完成高度脸部辨识准确性(state-of-the-art accuracy)。这中间需要解决的挑战包括:将深度学习模型整合到操作系统,使用宝贵的 NAND 储存空间(一种非挥发性储存技术,即电源切断后仍能储存资料);还要将其加载到 RAM(随机存取存储器),利用 GPU 和/或 CPU 达到合适的计算时间;此外,和云端深度学习模型不同的是,终端机深度学习还需要解决执行电脑视觉指令的同时,还有其他的背景程序。
总言之,终端机深度学习模型要求的是:针对大型的照片资料库,用极短的时间执行指令,并使用不多的功耗或说不发烫。
二、从维奥拉─琼斯到深度学习

2001 年,Paul Viola 和 Michael Jones 基于哈尔特征和方向可变滤波器,提出了基于简单特征的对象辨识技术,此即维奥拉─琼斯目标侦测框架,这个方法在 OpenCV 中实现为 cvHaarDetectObjects()。基于维奥拉─琼斯框架,iOS 7 引入 CIDetecor,做到了人脸侦测、辨识功能,但此时的人脸辨识,准确性和可靠性都不成熟。
2014 年,苹果最开始着手基于深度学习的脸部辨识,深度卷积神经网络(DCN)才刚能完成物体辨识工作,当时的主流方案是 OverFeat(利用卷积网络特征撷取算子,以达到图片分类、定位和侦测),能有效快速扫描物体影像。
OverFeat 实现了神经网络的连线层与卷积层(相同空间维度的滤波器的有效卷积)之间的等价性,也就是做到多尺度汇入预测(裁一个 32×32、像素尺度 16 的区域,可汇出任意大小,比如 320×320 的影像,生成适当大小的汇出对映,比如 20×20)。此外,OverFeat 还提供基于更少网络步幅的更密集汇出对映。
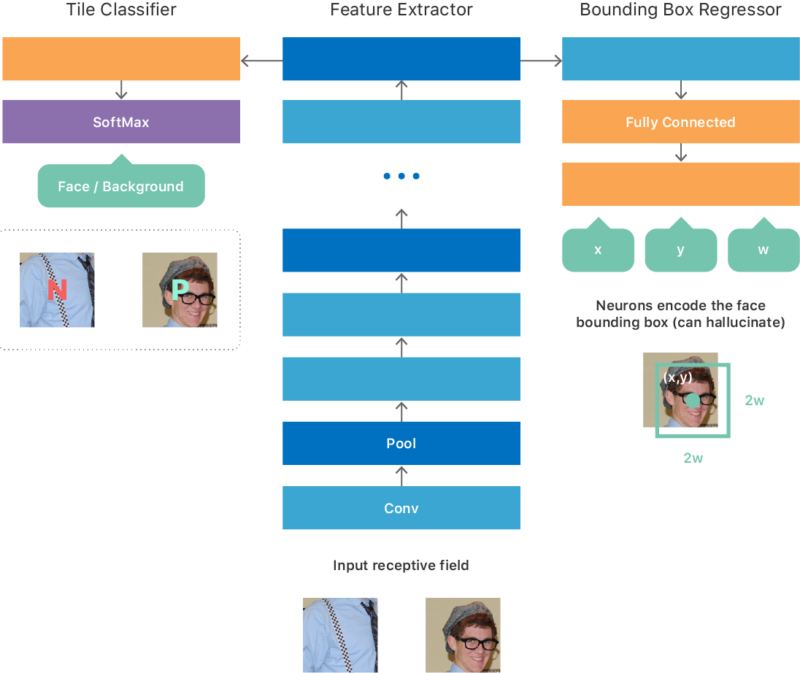
基于 OverFeat,苹果搭建了初始架构,以实现:
- 二进位分类:辨识汇入资料中是否有脸部资讯;
- 回归演算法:边线预测汇入的人脸资讯,达成人脸定位。
苹果尝试一些训练方式:建立一个固定大小的影像块大资料集,对应网络的最小有效汇入,使每个块产生来自网络的单个汇出;定义参数的正负类,训练网络来最佳化多工作目标,如辨识是否有人脸,找出人脸的座标和缩放比例。高效的完全卷积可处理任意大小的影像并生成二维汇出图。
整体思路是这样的:在人脸侦测流程中,包含多尺度的影像金字塔、人脸侦测器以及后处理模组等三大部分。多尺度的金字塔处理各种大小的面孔;人脸侦测器贯穿金字塔的各个等级,并从每层收集候选侦测;后处理模组然后组合这些候选侦测结果跨度,以产生对应网络对影像的脸部最终预测的边线框清单。
上述策略基本构成终端机电脑视觉方案,但网络复杂性和规模仍然是效能的关键瓶颈,不仅要将网络限制在一个简单的拓朴架构中,且还要限制网络层数,每层信道数量和卷积滤波器的核心大小。
为此,苹果提出了“师生”培训方式,即利用已培训的大型复杂网络(“老师”)汇出,来培训第二个薄而深的网络(“学生”,一个简单的 3×3 卷积和层叠重复架构组成,它的架构经过设计,能最妥善利用苹果自家神经网络推理引擎)。
以上方案是适合终端机用于脸部侦测的深度神经网络算法,并透过几轮训练更新,实现了够精确的网络模型。
三、最佳化影像管道
深度学习提供一个很厉害的电脑视觉框架(Vision Framework),但它还需要高度最佳化的成像管道。
不管汇入影像是什么角度、有无缩放、什么色彩转换或影像源/格式,人脸侦测都应该执行良好。此外,功耗和存储器使用情况也是最佳化的关键,特别是流媒体和影像撷取。对此,苹果采用部分二次取样解码技术和自动平铺技术,即使在非典型的纵横比下,也能在大影像执行电脑视觉工作。
此外,苹果还提供了广泛的色彩空间 API,电脑视觉框架可直接处理色彩匹配,降低开发人员的相关应用开发门槛(不用承担色彩匹配工作)。
电脑视觉框架还透过有效处理和重复使用中间体来最佳化。透过将算法的界面抽象出来,找到要处理的影像或缓冲区的所有权位置,算法框架可建立和缓冲区中间影像,提供尽可能多的分辨率和色彩空间,以提高多台电脑视觉工作的效能。
四、最佳化终端机效能
如前所述,终端机人脸侦测 API 必须克服即时应用程序和背景系统程序的问题。用户要的是处理照片资料库的同时辨识人脸,或在拍摄后立即分析照片,流畅执行人脸侦测,还不影响功耗,系统不卡顿。
对此,苹果的方案是最大限度地减少使用存储器和 GPU,即透过分析计算图来配置神经网络的中间层:将多个图层代号到同一缓冲区,既可以减少存储器使用,又不会影响效能或规格碎片,且可在 CPU 或 GPU 使用。
苹果电脑视觉的框架的侦测器执行 5 个网络(即对应 5 个比例的金字塔),共用相同的权重和参数,但其汇入、汇出和中间层具有不同形状。为了进一步减少使用空间,不妨在 5 个网络组成的联合图上执行基于活性的存储器最佳化算法。此外,多个网络重复使用相同的权重和参数缓冲区,也可减少存储器需求。
利用网络的完全卷积性,将所有影像都动态调整到汇入影像的分辨率,也能大大减少总作业数量。由于作业拓朴架构并没有因分配其余部分的重构和高效能而改变,所以动态整形不会引入与规格有关的性能开销。
为了确保深层神经网络在背景执行时的 UI 回应性和流畅性,苹果为网络每层分割 GPU 工作项,直到每个单独时间少于 1 毫秒。所有这些策略综合起来,确保用户可享受本地、低延迟、隐私保护的深度学习算法,而不会意识到手机每秒执行数百万浮点的神经网络。
(本文由 MacX 授权转载;首图来源:苹果)



